Vấn đề: với một người rất hay đọc báo/blog online như mình, chức năng Reader của Safari rất hữu dụng. Chức năng này rất đơn giản, mỗi khi bạn truy cập vào một trang web nào đó(chủ yếu là trang web về tin tức), khi bạn dùng Reader, nội dung chính của trang web sẽ được hiển thị riêng ra, các phần khác như menu, quảng cáo… đều bị ẩn đi, font chữ được phóng to lên, giúp cho bạn tập trung vào bài báo dễ dàng hơn.

Tuy nhiên, một nhược điểm của Reader là chỉ có Safari mới có, nghĩa là phải dùng Mac hoặc iOS thì mới dùng được. Chuyển qua Linux, hoặc dùng các trình duyệt khác thì bó tay. Vì vậy mình thử viết một ứng dụng web nho nhỏ để giải quyết vấn đề này xem sao.
Yêu cầu: một ứng dụng web đơn giản, cho nhập vào địa chỉ một bài báo(hay một link blog), ứng dụng sẽ tự động lấy nội dung của trang web đó về, tách bỏ các phần râu ria đi, chi hiển thị nội dung chính của bài báo đó.
Đây là ứng dụng mình demo trên Heroku, dùng Ruby on Rails, cùng với thư viện parse XML Nokogiri.
Link một bài báo sau khi đã tách được nội dung chính: Đi trên những cây cầu kỳ lạ nhất thế giới
Sau khi đã tách nội dung chính: hiển thị như thế này
Trở lại vấn đề, mình có 2 hướng giải quyết:
- Dùng một số đánh giá Heuristic đơn giản để lựa ra phần có nội dung có vẻ là nội dung chính nhất.
- Dùng Machine Learning/Statistic: cho một số pattern mẫu vào training set, dùng các thuật toán Supervised Learning để giúp nhận dạng được các pattern khác.
Cách 2 có vẻ khoai, nên thử cách 1 trước xem sao!
Trước hết ta có quan sát đơn giản như sau:
Quan sát 1: Nội dung chính thường chứa nhiều text hơn link. Điều này khá hiển nhiên, nội dung chính mà chỉ toàn link, kèm theo vài đoạn text thì chắc là spam rồi.
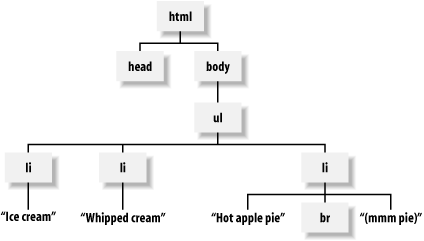
Trước khi đi vào thuật toán, mình xin nhắc lại một chút về HTML.
Một tài liệu HTML(hay XML) có thể biểu diễn thành dạng cây, với mỗi một node là thẻ HTML.
Từ quan sát trên ta phát thảo một thuật toán như sau:

Ta cần điều chỉnh p, q sao cho ra kết quả chính xác nhất. Có thể đánh giá dựa trên các tỉ lệ precision, recall, … Hiện tại mình đang dùng p = 0.99, q = 0.01
Đến đây thì thuật toán của ta cũng gần gần hoàn thiện, nếu tinh chỉnh hệ số p, q thích hợp độ chính xác khá cao.
Trong những bài sau, mình sẽ trình bày một số cái tiến khác, đồng thời thử áp dụng cách thứ 2 xem có hiệu quả hơn không.
Cám ơn mọi người đã theo dõi và mong nhận được ý kiến đóng góp!
Xuân Vinh-BSE ZIGExN VeNtura


![Company Trip 2017 [Part 3: Gala Dinner]](https://blog.zigexn.vn/wp-content/uploads/2017/01/IMG_7813.jpg)
